In our definition, live streaming is a feature of an application that allows you to transmit video over the network as you shoot your video, without having to wait until recording is complete. In this post, we are going to discuss how we have tackled this problem while developing the Together video camera app for iOS.
Together video camera is an iPhone application which allows you to shoot videos and easily manage your video collection, sorting it both automatically by date, location, tags, and manually by albums. You can also synchronize your collection between devices and share your videos and streams with your friends.
At the very onset of the development lifecycle, we had conceived Together as a teleconferencing application , then we shifted our focus to one-way live streaming to a large audience, like in LiveStream or Ustream. And, having finally approached our first public release, we have converted the application into a personal video library manager.
At the first glance, supporting live streaming is not a big deal. There are lots of well-known applications and services run by a variety of platforms that use this feature. It is the main feature for some of them, e.g. Skype, Chatroulette, Livestream, Facetime, and many others. However, the iOS standard development tools and libraries prevent optimal implementation of this function, since they fail to offer a direct access to hardware-based video encoding features.
From the implementation viewpoint, live streaming can be broken down into the following sub-tasks:
- Get the stream data while shooting.
- Parse the stream data.
- Convert the stream into the format supported by the server.
- Deliver the data to the server.
Here are the following basic requirements for the app to implement live-streaming:
- Ensure a minimum delay between video shooting and its display to the consumer.
- Ensure the minimum amount of data sent over the network while maintaining acceptable quality of picture and sound.
- Enable optimal utilization of CPU, memory, and storage capacity of the shooting device.
- Minimize the battery drain.
Depending on the purpose of live streaming in the app, certain requirements may dominate. For instance, the requirement to minimize the battery drain is in conflict with minimizing delay, as sending large chunks of data across the network may be more energy efficient than maintaining a connection constantly exchanging the data while shooting. Our Together app is not focused at getting feedback from the viewers in real time; but, at the same time, we offer you the opportunity to share videos you shoot as soon as possible. Therefore, the requirement to minimize the battery drain has become a top priority for us.
iOS SDK includes a fairly rich set of features to interact with the camera and handle video and audio data. In our previous posts, we have already told you of the CoreMedia and AVFoundation frameworks. Such classes as AVCaptureAudioDataOutput or AVCaptureVideoDataOutput combined with AVCaptureSession can retrieve frame-by-frame picture from the camera in the format of uncompressed video and audio buffers (CMSampleBuffer). The SDK is supplied with sample apps (AVCamDemo, RosyWriter) illustrating how to work with these classes. Before transmitting buffers obtained from the camera to the server, we have to compress them with a codec. Video encoding at a decent compression ratio usually involves substantial CPU time utilization and, accordingly, battery drain. The iOS devices have special hardware for fast video compression with an H.264 codec. To make this hardware available to developers, the SDK provides but two classes differing in ease-of-use and features:
- AVCaptureMovieFileOutput outputs the camera image directly to a MOV or MP4 file.
- AVAssetWriter also saves video to a file, but in addition to that it can use frames provided by the developer, as a source picture; such frames can be either obtained from a camera as CMSampleBuffer objects, or generated programmatically.
Lets analyze CPU time spent on H.264 video encoding using standard SDK libraries and FFmpeg in the FFmpeg-iOS-Encoderproject. We ran our benchmarking using the Time Profiler tool, shooting and simultaneously recording a video file at a resolution of 1920×1080.
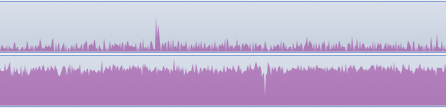
In the first graph, you can see video recording with the AVAssetWriter class. CPU utilization before and after the recording starts is almost constant. Part of the encoding load is transferred to the mediaserverd system process, but even in view of this the total CPU utilization is rather small, and the video is shot smoothly, at no interruption and the frame rate of 30fps.
In the second graph, you can see the video recorded with FFmpeg libraries using the MPEG4 codec and video resolution down to 320 x 240. In this case, the CPU utilization is nearly 100%, but the video is recorded at a rate of only 10-15fps.
While sending video over a network, an ideal option would be to skip data saving to the disk but to feed compressed data directly into the application’s memory. But, unfortunately, the SDK is not providing for this, so the only thing left is to read compressed data from a file the system writes to.
An attentive reader would probably recall that iOS is a UNIX-like system from inside, and such systems usually have a special type of files called named pipes allowing you to read and write to a file, without involving any disk resources. However, AVAssetWriter fails to support this type of files, as it writes the data not continuously, but sometimes it has to return back and append missing data; this may be needed, for instance, to fill out the mdat atom field length in a MOV file.
To read data from a file which is currently appended to, the easiest way is to run a cycle to read new data appended to the file ignoring the end of the file character until appending to the output file is not complete:
[gist id=7152532]
Such an approach is not very efficient in the context of resource utilization as the application is unaware when the new data has been appended to the file and has to access the file constantly, regardless of whether the new data has emerged or not. This downside can be overcome by using the dispatch_source function of GCD, an asynchronous input/output library.
[gist id=7152637]
The resulting data will be presented in the same format they are saved by iOS, i.e. in the MOV or MP4 container format.
The MOV video container format (also known as the Quicktime File Format) is used in most of Apple’s products. Its specification was first published in 2001: based on it, the ISO has standardized its MP4 format which is more widely used today. MOV and MP4 are very similar and differ only in some small details. The video file is logically divided into separate hierarchically nested parts called atoms. MOV specification describes about fifty different types of atoms, each of which is responsible for storing specific information. Sometimes, to correctly interpret the contents of an atom you have to first read another atom. For example, a video stream encoded with an H.264 codec is stored in the mdat atom; to correctly display it in the player, you need to first read the compression parameters from the avcC atom, read frame timestamps from the ctts atom, read the boundaries of individual mdat frames from the stbl atom, etc.
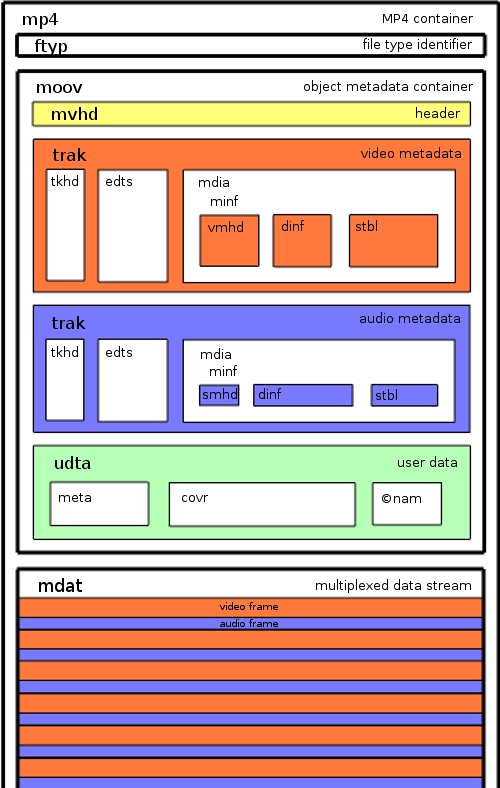
Most players cannot play back a video stream as it arrives from an uncompleted MOV file. Moreover, to optimize transmission of video to server and data storage, video stream shoud be converted into another format or at least parsed out into individual packets. The task of video transcoding can be delegated either to the server part or to the client part. In the Together camera, we have chosen the second option, as transcoding is not likely to involve much computing resources, but can, at the same time, help you to simplify and offload the server architecture. The application immediately transcodes the stream into a MPEG TS container and cuts it into 8-second segments which can be easily transmitted to the server in a simple HTTP POST request with the multipart/form-data body. Such segments can be used immediately, without any further processing, to build a broadcast playlist via HTTP Live Streaming.
Specific structure atoms inside a common MOV file, makes it impossible to apply this format to streaming. To decode any part of a MOV file, a complete file shall be available, as decoding-critical information is contained in the end of the file. As a workaround for this problem, an MP4 format extension has been proposed to record a MOV file consisting of multiple fragments, each of which containing a separate block of video stream metadata. For AVAssetWriter to start writing a fragmented MOV, it is sufficient to specify the movieFragmentInterval value constituting the fragment length.
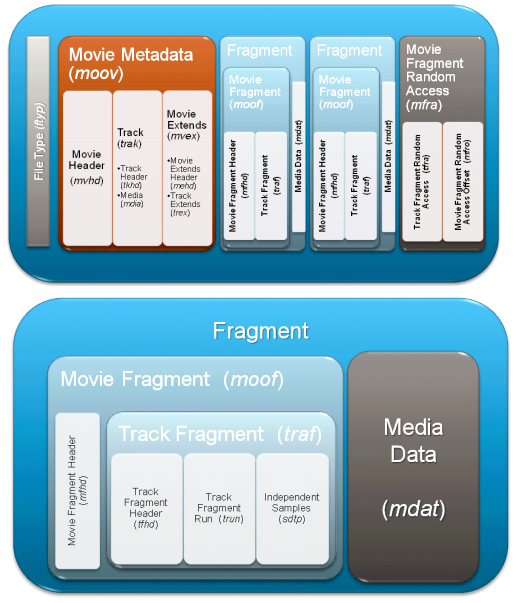
Fragmented MP4 (fMP4) is used in streaming protocols, such as Microsoft Smooth Streaming, Adobe HTTP Dynamic Streaming, and MPEG-DASH. In Apple’s HTTP Live Streaming this purpose is served by the MPEG TS stream broken into separate files called segments.
Before iOS 7, another more sophisticated way to read an incomplete MOV file existed which could do without MOV fragmentation. You could parse the contents of mdat, identifying specific NALUs (H.264 codec data blocks) and AAC buffers. Each NALU and AAC buffer in the output file corresponded to each input sample buffer and exactly followed the recording order. Because of this, you could have easily established correspondence between a NALU, a frame and a frame timestamp. This information was sufficient to decode the video stream. In iOS 7, this clear correspondence was complicated. Now, each input sample buffer can have one or more NALU, and it is impossible to identify how many of them can exist for each particular frame.
For video stream transcoding we used the most intuitive solution: an open set of FFmpeg libraries. With the FFmpeg libraries, we have succeeded in solving the issue of parsing a fragmented MOV file transcoding packages into a MPEG TS container. FFmpeg can relatively easily parse a file submitted in any format, convert it to another format, and even transmit it through the network via any of the protocols supported. For example, for the purposes of live streaming you can use the FLV as an output format, and RTMP or RTP as protocols.
To connect FFmpeg to an iOS application, you need to compile static FFmpeg libraries in several versions existing for different architectures, add them to your project in Xcode, open build settings and add FFmpeg header files path to the Header Search Path option. To cross-compile libraries for iOS, before building FFmpeg run the configure script specifying parameters for the path to iOS SDK and a set of functionality to be included into the build. The easiest way is to download one of the multiple ready build scripts available on the Internet (1, 2, 3, 4) and customize it to your needs.
However, FFmpeg does not fully support such a model we had to implement in Together. So that reading from the recorded file is not interrupted at the end of the file, we wrote a protocol module for FFmpeg called pipelike. To slice segments for HTTP LS, as a basis we used one of the earliest versions of the hlsenc module called libav and revised it, fixing bugs and adding the feature of transmitting the output data and the main module’s events directly to other parts of the application through callbacks.
The resulting solution has the following advantages and disadvantages:
Advantages:
- Optimal battery consumption, at the level in no way inferior to standard Apple’s applications. This has been attained by utilizing the platform’s hardware resources.
- We have made the maximum use of standard iOS SDK, with no private APIs, which makes the solution fully App Store compatible.
- Simplified server infrastructure attained through transcoding of HTTP LS video segments at the application side.
Disadvantages:
- Delay from shooting to playback is about 90 seconds.
- The video file is written to a disk, meaning that:
- A streamed video cannot exceed free space available on the flash drive.
- During streaming, the flash disk resource deteriorates with each data overwrite.
- Disk space that could have been used for other purposes gets crammed.
So, what contributes to the delay:
- Transfer a frame from the camera to the application: milliseconds.
- Write the buffer to the file: milliseconds.
- Read the buffer from the file (including delay due to file write buffering at the operating system level and video encoding algorithm used) 1-3 seconds.
- Fragment read completion: up to 2 seconds (fragment duration).
- Segment generation completion: up to 8 seconds (segment length).
- Send a segment to the server: 2-10 seconds.
- Generate a playlist: 2 seconds.
- Client’s delay before requesting a new playlist: 9 seconds (Target Duration value set in the playlist).
- Load and buffer segments on the client: 27 seconds (three Target Durations).
Total: 60 seconds. Other delays in the Together live streaming are caused by the specifics of implementation:
- The reason behind such a delay is that the system starts reading the next segment only after the previous segment has been fully sent.
- Delay due to the time elapsed from starting to write the file to streaming launch by the user (the file is always streamed from its beginning).
Most of the factors affecting the delay are due to the HTTP LS protocol. Most of live streaming applications use such protocols as RTMP or RTP, which are better tailored to streaming with a minimum delay. We also researched into a few other applications having the live streaming function, such as Skype and Ustream. Skype has a minimum delay of about one second while utilizing 50% of the CPU. It brings us to the conclusion that they use a proprietary protocol and algorithm to compress video data. Ustream uses RTMP, has a delay of 10 seconds or less and generates a minimum CPU utilizaton, just as with hardware video encoding.
All-in-all we have resulted in acceptable live streaming satisfying requirements of the Together Video Camera.
Here are some other developments that use a similar approach to live streaming:
- Livu is an application that can stream video from the iOS device to an RTP server. As it is not a full-scale streaming service, you’ll have to specify your own video server. On github you can find a pretty old version of the app’s streaming component. Livu’s developer Steve McFarlin is often consulting at Stack Overflow on video app development issues.
- Hardware Video Encoding on iPhone – RTSP Server example: here you can find the source code of an application implementing live streaming from iOS.
See also our previous posts on iOS-based video app development: