Hardly any project today can avoid storing of a large amount of media objects (video chunks, photos, music, etc).
In our projects, we often needed our storage system to be highly reliable, as loss of content often results in service interruption (I think this is true for most of the projects). Moreover, as the service capacity grows, such characteristics as performance, scalability, manageability, etc., become of key importance.
To enable content storage, you can use different distributed file systems, however each of them obviously has its own upsides and downsides. So selection of an optimum file system is in no way a trivial task. Recently, we have been solving such a task for our Together project, an innovative mobile video content platform to handle user-generated content just like Netflix handles movies. Then, we have started using the platform in other our services, such as: PhotoSuerte to store photos and Veranda to store short videos. In most of our projects, the platform has proven itself efficient. In this post, we would like to tell you how to create a distributed data storage for a video platform.
First of all, you have to define requirements for the storage system under design. Also, you have to take into account that the requirements often change due to many factors. In this respect, we have in no way been an exclusion, so while solving some issues we discovered new use cases to enhance our functional requirements.
Here is our list of preliminary data storage requirements:
- Concurrent saving (RW mount from multiple points)
- POSIX compatible
- Mountable on clients without building any patched kernels, modules, etc. (compatibility with any cloud)
- Fault-tolerance
- Scalability (both upscale and downscale) on-the-fly, without any performance degradation
- Easy-to-use storage administration interfaces.
Basic solution options
1. Hardware based network storages – NetApp / Oracle (Sun), etc.
Such solutions can help to ensure a reliable data storage, sometimes even with distributed features support. However, they are madly expensive. In fact, this option is generally not an option at all for a startup.
2. Dedicated servers crammed with disks.
Not many of such solutions exist; for example, a Russian-based vendor is http://bitblaze.ru/. The guys from BACKBLAZE have been first into it far back in 2009. In their blog, you can find a series of posts on assembling such servers.
Such solutions can provide a low-cost data storage, but make us ponder over implementation options or installing software to handle the data. In other words, to implement a distributed storage we need a distributed file system. This we are going to discuss below.
To enable storage nodes for this solution, you can rent dedicated servers in different data centers.
We have researched multiple options. However, the most cost-effective one, in our opinion, is Hetzner. For just 50 euros you can get a 2TB data storage. Outside of Europe, however, it is usually problematic to find cost-effective dedicated servers.
3. Cloud infrastructure
Many providers offer storage services today, such as:
- Amazon S3
- Rackspace Cloud Files
- Google Cloud Storage
- Microsoft Azure Storage
- Softlayer Object Storage
- GoGrid Cloud Storage
- DreamObjects Cloud Storage
- OVH Public Cloud Storage.
They are quite costly, perhaps only the last is worthy of attention: its storage cost is among the lowest, and the traffic is several times cheaper compared to competition. While estimating for this option, please also be aware that you can avoid the cost of “engineering” needed to support and maintain your storage.
Options for Distributed File Systems
Dedicated servers are most appealing in terms of price. However, to implement a distributed storage you need to seek for relevant software.
In this context, the following software products are among the popular today:
– Ceph
– GlusterFs
– nimbus.io
– DRBD
– GPFS
– Lustre
– MogileFS
– TahoeLAFS
– Elliptics.
All these solutions can be typified as an Object Storage and a POSIX-compliant File System Storage (it can sometimes be implemented with FUSE or native solutions).
As for us, we had been long seeking a POSIX-compliant solution. To us, it had seemed more familiar and manageable. However, we had no compelling arguments against an Object storage, although bulk data operations are sort of sophisticated in this case.
DRBD was absolutely not an option, as it is no more than a network-based RAID that provides for fault tolerance, but dynamic expansion of storage is absolutely out of question.
nimbus.io is an interesting project, but we did not find much reviews on it, so we decided not to expend time testing it.
Lustre had, until some time, had an issue of support by the Linux kernels. As our infrastructure is cloud-based and we cannot always control the image run on virtual machines, we could not have taken the risk. In our opinion, another downside of implementing solutions like Lustre is related to coordinating nodes that store metadata, as they can create an additional point of failure with a strong need for redundancy. And, in general, the solution seemed too monstrous.
CEPH has received lots of positive feedback, a couple of small tests has been run, so it’s working. But the system has not been really time-proven.
GlusterFS: we tested it in version 3.3.1, mounting volumes via NFS using a native client. We have experienced some problems with failed limits; also at volume truncation (node removal) some data was lost.
With Elliptics, we have spent the maximum time testing and comprehending how it works, and have concluded that this is the most successful solution so far. We began our testing when no public repositories have been available and building was feasible but on Ubuntu only. We had almost no documentation: just blog posts and conference speeches. The first misunderstanding we had with the concept of replication. In the classical sense, there is no such thing as replication here (like in MySql/Mongo/Redis, etc.). Data replication is implemented by a client that writes data directly to the required number of groups. As an alternative to writing the data itself, you can write the data into one group, and metadata to the other groups. Subsequently, when group reconciliation is started manually, the data is copied between the groups. Certain difficulties arise due to non-uniform distribution of data across the storage in case the nodes have storage capacity below 100GB; however, this can be solved very easily, by “manual” adjustment of key ranges served. Another downside is lack of “out-of-the-box” product or of an HTTP interface to access the data. However there is an intuitive Python-based binding which, when used with Bottle, can help make an HTTP interface in just a few hours. To make a quicker solution, you can use a C-based binding. In fact, there is a solution run as a small HTTP server (libswarm + theVoid), but it’s more of a demo.
Elliptics Based Storage
Elliptics is an open-source distributed key/value storage. By default, it implements a hash-table distributed between all the cluster nodes. Elliptics is not using any individual management or control nodes that may create a potential single point of failure; also, it supports replication between data centers with flexible I/O balancing.
Elliptics’ is built around a P2P model. So Elliptics supports not only atomic I/O operations, but also has an interface to implement server-side data processing; there are specific interfaces for it in different languages (Python, Perl, JavaScript). Also, there are flexible interfaces to create plugins allowing you to make a low-level backend for an in-memory storage.
As a backend, Eblob is used quite commonly. This is a local append-only low-level data storage. It combines a high read/write performance, many features and easy configuring. The main purpose of its creation was to implement a bullet-proof backend for Elliptics.
Since our nodes are geographically located in different parts of the world, obviously the load should be balanced between them. The data is written in parallel to all the groups that we need. The server part that implements saving of content to the repository decides when to tell the user that the data has been saved successfully, and release the user. It can do it after the data has been written to one, two or even all of the groups.
With the above-mentioned meaning of “replication” in mind, we can use several options to save the data. All this depends on how much you care about the data, and whether you can compromise on data loss in favor of performance.
The data is read with an HTTP proxy configured to connect to one of the nodes and retrieve full details of nodes in the cluster.
Based on the hash ring received, the data can be written to specific nodes within groups set in the configuration file. The client is released only when the data has been saved completely.
The easiest method to integrate Elliptics into projects is to run it via such HTTP interfaces as TheVoid/Swarm. In this case, to include a storage infrastructure in the existing project all you need is to use HTTP GET and HTTP POST from your existing code. Also, you can develop a custom client for you.
At the moment, there are bindings for Python and C.
You can find details on TheVoid/Swarm installation and use here: http://doc.reverbrain.com/elliptics:client-tutorial
Info on bindings:
С++: http://doc.reverbrain.com/elliptics:api-cc
С: http://doc.reverbrain.com/elliptics:api-c
Python: http://doc.reverbrain.com/elliptics:api-python
Data structures: http://doc.reverbrain.com/elliptics:api-low-level-data-structures
Eblob API: http://doc.reverbrain.com/eblob:api:api
There has been no administration utilities available until recently.
Commonly, the following utilities are used:
• dnet_recovery allows you to check the hash ring and, if necessary, to restore it. Also, it allows you to recover one group based on another group.
• dnet_ioclient is a console client to read/write data.
• dnet_stat provides cluster statistics (memory usage/LA/IO)
• dnet_ids allows you to generate an IDS either based on the blob file content or randomly.
• eblob_index_info shows the number of keys in the blob (including those marked as deleted)
• eblob_merge allows you to merge multiple blobs into one.
Just recently, a tool has been announced to allow an administrator to monitor the cluster status. It is called the Mastermind.
This application is launched from the recently released cloud service called Cocaine by a Russian search giant, Yandex.
It allows you to:
- Collect and provide information on all your groups and their status (consistency)
- It can run as a balancer and instruct the clients where to save data
- It supports operations with groups (replicas).
More information can be found here: http://doc.reverbrain.com/elliptics:mastermind
Testing
We have run our tests in the DigitalOcean cloud.
Storage nodes are 8 instances costing $10 and having the following characteristics:
- 1GB Memory
- 1 CPU Core
- 30GB SSD Disk
A node with an HTTP proxy (Swarm):
- 8GB Memory
- 4 CPU Cores
- 80GB SSD Disk
Testing node:
- 2GB Memory
- 2 Cores
- 40GB SSD Disk
The dataset contains ~30k objects, 2-30MB each. Swarm has been launched with 60 threads.
Our numerous tests have proven that under such conditions it is the network performance rather than the repository performance that accounts for the bottleneck. The disk subsystem of the storage nodes has been loaded by no more than 5%.
As a result, we have decided to run a benchmark test, as the growth in concurrency affects response times.
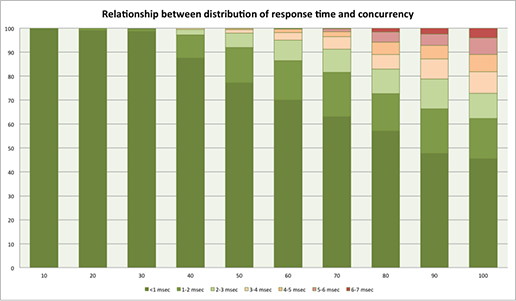
The graph shows that under the shortage of network resources response times decrease fairly smoothly, without any sharp drops. Denials of service were also not observed which we cannot help but rejoice.
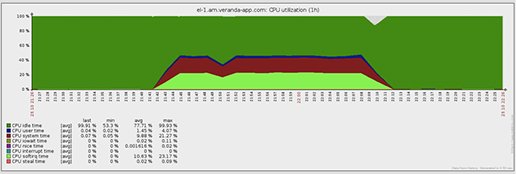
The load on the CPU, however, is not so high.
CPU usage (proxy)
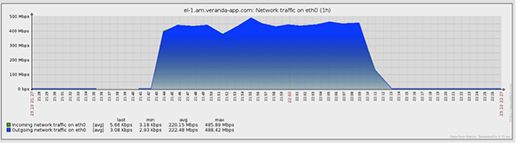
Traffic (proxy)
From all this we can conclude that with Elliptics we can relatively quickly and cost-efficiently deploy a Distributed Storage System to provide: high data availability, a transparent and flexible data access interface, high performance, and easy scalability to accommodate limited resources and cloud-based infrastructure specifics.
For ourselves, we have also realized that while considering the final solution you should not necessarily focus at what you feel is “easy-to-use” at the first glance (POSIX). On the reverse, this may add to integration difficulties.