В статье пойдёт речь о том, как визуализировать вейвформу оптимальным образом, что для этого подходит лучше – CAShapeLayer или drawRect(), а также о некоторых тонкостях работы со Swift. Информация будет полезна не только тем, кто разрабатывает сложные кастомные UI компоненты и работает со звуком, но и любым iOS-разработчикам для расширения кругозора.
Постановка задачи
Разработчики DENIVIP создали приложение для фильтрации шумов в аудиозаписи – Denoise. Для пользователя это выглядит примерно так: он выбирает видео из своего альбома, приложение строит вейвформу звуковой дорожки и пользователь может выбрать на ней область с шумом, который нужно подавить. После небольшой магии пользователь получает видео с отфильтрованным звуком.
Алгоритм подавления шумов в данной статье подробно не обсуждается, но по большому счету он не выходит за рамки университетской программы по цифровой обработке сигналов. Теоретическую базу можно найти в удобном виде на сайте MITOpenCourseWare. Если говорить очень кратко, когда пользователь выбирает участок с шумом, мы, используя прямое преобразование Фурье, получаем частотный спектр «шумного участка». Запомнив эти частоты как «плохие» и требующие подавления, алгоритм проходит по всей аудиодорожке, на каждом участке получает частотный спектр и применяет подавляющие коэффициенты к «плохим» частотам. Затем, после применения обратного преобразования Фурье, получается новая вейвформа (дискретные звуки), в которой шумы существенно подавлены. Вся сложность состоит лишь в том, как качественно выбрать «шумный» участок. При этом чем длиннее видео, тем важнее становится интерактивность вейвформы, т.к. пользователю может потребоваться выделить несколько секунд аудиодорожки в середине двухчасового видео.
В первую очередь нам необходимо отобразить звуковую дорожку в понятной для пользователя форме и при этом дать ему возможность манипулировать ею (изменять масштаб, перемещаться по ней, выделять фрагмент). Сразу замечу, что если мы попытаемся отобразить все сэмплы нашей аудиодорожки, то может оказаться, что, во-первых, нам не хватит памяти, а, во-вторых, процессор (а заодно и GPU) “захлебнется” от такого количества точек.
Пример. Для 10-минутного видео 16-битная стерео аудиодорожка с частотой дискретизации 44,1 кГц будет «весить» 10 * 60 * 2 * 44100 * 2 ~ 100 MB. При этом большая нагрузка ложится и на GPU.
Очевидным решением будет разбить сигнал на равные интервалы, посчитать, например, средние значения на этих интервалах и полученный набор (средних) использовать для отображения вейвформы. На деле будем использовать средние и максимальные значения на интервалах — для каждой аудиодорожки будем строить 2 вейвформы одна над другой. Плюс может потребоваться добавлять вейвформы «на лету” (для отображения отфильтрованного сигнала поверх оригинального). Существенным усложнением данного подхода является необходимость изменять масштаб вейформы, а также «перемещаться» по оси времени для выбора нужной области.
Замечу, что чтение сэмплов из аудиофайла и построение вейвформы может занимать продолжительное время. Для примера, на iPhone 5s вейвформа для 10-минутной записи строится порядка 10 секунд. Как известно, хуже ожидания для пользователя может быть только отсутствие информации о том, сколько еще нужно ждать. Поэтому мы решили сделать отрисовку загружающейся вейвформы анимированной, чтобы пользователь видел прогресс в интуитивном формате.
Итого для решения задачи нужно:
-
Уметь читать одиночные сэмплы аудиодорожки и строить по ним данные для отображения вейвформы
-
Уметь рисовать несколько вейвформ (с возможностью добавлять вейфвмормы в любой момент).
-
Иметь возможность рисовать вейвформу “анимированно” по ходу чтения сэмплов.
-
Добавить возможность масштабировать вейвформу и смещать её по времени.
Существующие решения
Лучшее из найденных решений: EZAudio. В целом интересный фреймворк, но он не совсем подходит для нашей задачи. Например, в нем нет возможности масштабирования графика.
Для отрисовки графика можно было использовать CorePlot. Но в целом это решение показалось громоздким для нашей задачи (также, возможно, потребовалось бы отдельно поработать над оптимизацией отрисовки большого набора значений).
Разработка
Архитектура waveform-модуля
По задаче необходимо уметь отображать не только конечные данные, но и данные в процессе построения. Также напомню о необходимости реализовать зум и перемещение по оси времени. Исходя из этого, было решено сильно отвязать слой UI от данных, которые ему предстоит рендерить.
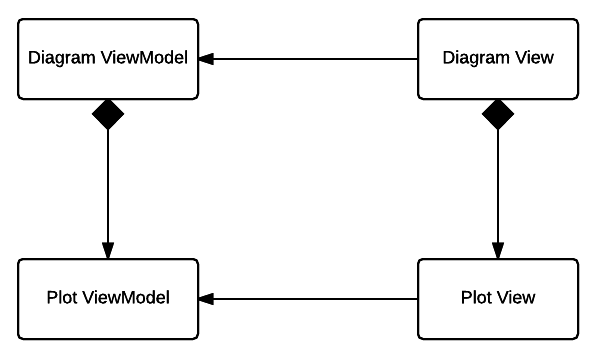
Примерно так упрощенно выглядят связи между классами, занятыми в отрисовке вейвформ.
Здесь
-
Diagram View — контейнер одиночных вейвформ. Он также реализует синхронизацию отрисовки вейвформ, для чего использует CADisplayLink.
-
Plot View — класс, занимающийся отрисовкой. Этот класс должен знать только ту информацию, которую необходимо отобразить в данный момент времени, и получать её он будет из соответствующего Plot ViewModel.
-
Diagram ViewModel — контейнер вью-моделей отдельных вейвформ.
-
Plot ViewModel — источник данных для одиночной вейвформы. Этот класс будет решать, какие семплы и в каком количестве отдавать на отрисовку, когда это необходимо
Здесь опущены протоколы, через которые на самом деле реализована связь от View к ViewModel. Замечу только, что архитектурой не предусмотрено обратных связей от ViewModel к View.
Благодаря такому подходу мы получили возможность оптимизировать построение данных для вейвформы и отрисовку вейвформы независимо друг от друга. Также это дало возможность внести серьезные изменения в построение данных без воздействия на слой View. Но обо всем по порядку.
Чтение сэмплов
Для построения вейвформы необходимо получить несжатые семплы аудиодорожки. Сделать это можно с помощью инструментов, предоставляемых фреймворками AVFoundation и CoreMedia.
Чтение данных целиком представлено в классе:
[gist id=c24531dfb4adb8ef7b60a67f6a1bd2b2 bump=2]
Не буду очень подробно останавливаться на этом коде. Скажу только, что перед началом чтения сэмплов можно узнать параметры аудиозаписи, такие как частота дискретизации и количество каналов (функция readAudioFormat), и использовать их при чтении. Но можно и пропустить этот момент и при настройке чтения использовать частоту, равную 44100 Гц, и читать по двум каналам. Глубину кодирования придется задать вручную (16 бит).
Также отмечу, что чтение сэмплов может занимать продолжительное время. Для видео в несколько минут время чтения будет порядка нескольких секунд. Поэтому алгоритм нужно использовать в фоновом потоке.
Обработка сэмплов
Следует помнить, что алгоритм чтения сэмплов, вообще говоря, выдает блоки разных размеров. В этом случае нам нужно последовательно обходить каждый новый блок сэмплов, и по ходу рассчитывать требуемые для построения вейвформ значения.
[gist id=fced3ba8b6fa654863bca2a16150b388 bump=2]
Swift vs ObjC. Что лучше?
Поскольку приложение уже было написано на Objective-C, начинать писать новый модуль на Swift было неочевидным решением. Например, что касается построения данных для графиков, требовалось убедиться, что Swift не создаст проблем с производительностью. Мы провели проверку аналогичных алгоритмов, написанных на обоих языках и использующих аналогичные типы данных (например, если в Swift использовался тип UnsafePointer<Double>, то в алгоритме на Objective-C — массив double*).
Результаты были следующие:
Данные по работе алгоритмов чтения аудиосемплов и построения данных для графика.
iPhone 5
Swift (Whole-Module-Optimization): 20.1 c
Objective-C (-Ofast): 41.4 c
iPhone 6s
Swift (Whole-Module-Optimization): 5.1 c
Objective-C (-Ofast): 4.1 c
Тесты проводились и на других моделях iPhone. Результаты показали сильные расхождения на моделях с 32-разрядными процессорами и небольшие — на 64-разрядных моделях. (Для дальнейшей работы над оптимизацией в основном использовался iPhone 5s).
Как видим, большой разницы нет. При этом некоторые особенности Swift очень помогли в решении этой задачи. Про это чуть ниже.
Масштабирование вейвформы
В первоначальном варианте для зума использовалась возможность чтения сэмплов из произвольного отрезка аудиодорожки. См. свойство объекта AVAssetReader
[gist id=d88bb2fad2ea196214e27ea7277691b5 bump=2]
И при каждом зуме графика чтение начиналось снова.

Вариант вполне рабочий, однако пересчет данных для отрезка требует примерно того же времени, что и расчет для всего аудиофайла: время порядка нескольких секунд (см. данные выше).
Рефакторинг обработки сэмплов
Для реализации плавного зума было решено попробовать другой подход. При чтении сэмплов можно строить данные для графика сразу для нескольких масштабов, выдавать на начальном этапе данные для исходного масштаба, а остальные наборы данных хранить в локальном хранилище (или в оперативной памяти) и отдавать их в UI по мере необходимости (а при зуме подменять один набор данных другим). Как мы уже упомянули, наша архитектура позволяет сделать это без необходимости изменений в UI.
Всю обработку блоков сэмплов мы обернули в отдельный класс, в котором реализовали хранилище для обработанных данных и возможность гибко менять логику обработки.
В качестве массива обработанных данных был использован UnsafeMutablePointer<T>, который по своей сути является аналогом массива на языке C (см. документацию (англ.): Структура указателя UnsafeMutablePointer, Взаимодействие с API языка C). Пример реализации брался отсюда.
[gist id=c0fb3081b149674d659bb7d8eb39628c bump=2]
Примечание. Здесь опущен очень важный момент: этот класс будет использоваться параллельно в разных потоках (запись в бэкграунде, чтение в главном потоке). В Swift встроенных средств для работы с многопоточностью нет, так что атомарное поведение буфера придется реализовать вручную (например, вот так). В нашем случае, при использовании Array<T> вместо UnsafeMutablePointer<T> и без синхронизации мы периодически сталкивались с выходом за границы массива. С UnsafeMutablePointer<T> такая проблема не возникала.
Про числовые типы
Пару слов скажу про ассоциированный тип T в классе Channel<T>.
Напомним, что для реализации зума было решено обрабатывать сэмплы и строить данные сразу для нескольких масштабов вейвформы. Поэтому нужно было добиться не только высокой производительности, но и эффективности при работе с памятью. Для нашей задачи для экономии памяти достаточно хранить сэмплы в Int16, а там, где нужно — явно приводить типы (благо стандартные числовые типы в Swift легко приводятся один к другому). Однако задача была решена в чуть более общем виде — то есть, с возможностью выбирать числовой тип для хранения данных. Для нашей задачи мы создали протокол для работы с числами любого типа (в Swift нет единого числового типа).
[gist id=f7d0a71ff6411e9a446a4b862493df9f bump=2]
Теперь в коде класса Channel можно указать следующее:
[gist id=b32e3a723349be40c0e87f4fa6338523 bump=2]
Параллельные расчеты для нескольких масштабов
Теперь можно в класс Channel добавить обработку сэмплов (например, нахождение максимумов).
[gist id=4a1fe32f34847c3dda309a64c0f73c03 bump=2]
Обработка (сразу по нескольким каналам, для нескольких масштабов) будет выглядеть примерно так.
[gist id=64ab536114e0e2fd9c89acfb6bdab5b2 bump=2]
Для получения конкретных данных будем запрашивать нужный канал. При зуме будем вызывать метод reset, что будет приводить к подмене текущего канала (при определенном масштабе).
По такому же принципу можно добавить вычисление средних значений. А чтобы все это работало вместе, можно создать один абстрактный класс Channel и 2 наследника MaxChannel и AvgChannel (для максимумов и средних значений, соответственно).
После всех манипуляций зум выглядит так:

Оптимизация
Построение набора данных для вейвформы
В общем, этого достаточно для решения задачи, однако мы попробовали оптимизировать алгоритм. Что касается Swift, если вам требуется высокая производительность того или иного алгоритма, то одними из главных препятствий станут ARC и динамическая диспетчеризация. Вообще говоря, в Swift есть ряд возможностей помочь компилятору опустить некоторые проверки. Здесь мы рассмотрим один из подходов.
Для оптимизации было сделано следующее:
-
Создали базовый класс, который инкапсулирует логику обработки сэмплов.
-
В классе-канале создали свойство этого типа.
-
В классе-логике создали слабую ссылку на класс-канал.
-
Отнаследовали от этого типа конкретные обработчики (для средних и для максимумов).
-
Сам класс-канал сделали ненаследуемым (с помощью ключевого слова final).
-
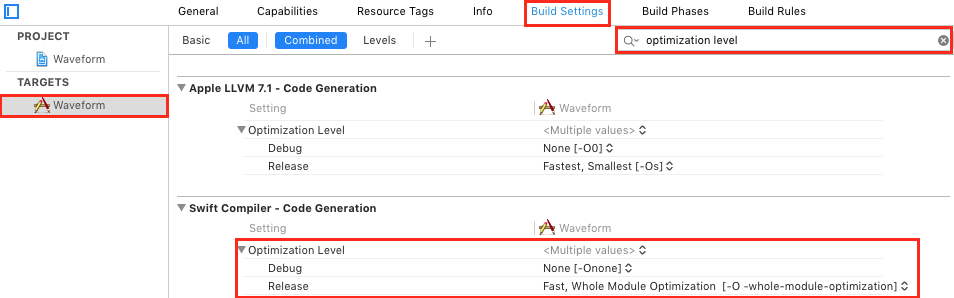
Включили оптимизацию Whole-Module-Optimization.
Про 2 последних пункта читайте здесь.
Режим Whole-Module-Optimization включается в настройках проекта.
[gist id=8e5220ed977713d51aa4831957bff202 bump=2]
Результаты сравнения скорости работы алгоритма (продолжительность видеоролика 10 мин):
В случае с наследованием каналов и логикой обработки внутри каналов время построения данных: 27.95 с
Для варианта с “внешней” логикой — 6.66 с
В конечном итоге, буфер также решено было спрятать внутрь отдельного класса для того, чтобы подружить класс Channel с ObjC (ObjC не умеет работать с обобщенными типами Swift).
Графика
Немного расскажем про работу с графикой.
По задаче требуется уметь рисовать большое количество вертикальных линий.
Исходный вариант
Изначальный вариант базировался на использовании CAShapeLayer и отрисовки с помощью линии обводки (stroke).
[gist id=dd1f08d4869e3b32ae487328b5361664 bump=2]
Время отрисовки для 2000 точек на каждую из 2 вейвформ, на iPhone 5s: 18 с
Вообще говоря, это рабочий вариант, однако для большого количества точек (порядка 1000), мы получали задержки при отрисовке кадров.
Вариант с оптимизацией №1 (построение CGPath без CGPathMoveToPoint)
Для начала избавились от использования функции CGPathMoveToPoint и там, где нужно, стали просто добавлять лишнюю линию вместо перемещения между точками.
[gist id=193e43e94307ff4295351966c96286e5 bump=2]
Время отрисовки для тех же исходных данных: 14.8 с.
Вариант с оптимизацией №2 (stroke против fill)
Вейвформы у нас довольно простые: строим линию от середины вверх в соответствии с уровнем сэмпла, повторяем симметрично вниз, возвращаемся на середину, переходим к следующему значению. Это позволило совсем отказаться от stroke и строить линии, закрашивая нужные области (fill). При этом по прежнему рисуем замкнутую фигуру.
[gist id=167b715f0ec665fc793f12fc46c598b8 bump=2]
В этом случае получаем: 12.4 с.
Прирост скорости небольшой и заметен только на относительно старых устройствах (до iPhone 5s включительно).
Вариант с оптимизацией №3 (drawRect против CAShapeLayer)
Также попробовали вместо CAShapeLayer использовать отрисовку того же самого CGPath в drawRect (алгоритм построения CGPath как варианте № 1)
[gist id=8e7a4b4acc44b6bb1725bdb8a027e6b6 bump=2]
Обращаем ваше внимание на то, что необходимо правильно выставить толщину линии, исходя из параметров экрана. Иначе преимущества в скорости вы не получите — отрисовка получится прерывистой и медленной. Также заметим, что здесь отключено ненужное сглаживание.
Результат теста: 9.46 c.
В итоге, в результате оптимизации построения CGPath и переходе на отрисовку в drawRect(), можно ускорить построение вейвформы почти в 2 раза. Полученного результата уже достаточно для плавной отрисовки нашей вейвформы.
Вместо заключения
- Как видим, Swift вполне подходит для задач подобного уровня.
- Оптимизация алгоритмов на Swift – это одна большая тема, которую мы еще постараемся осветить.
- Для достижения оптимальных параметров отрисовки вашей графики не обязательно переходить на OpenGL или Metal.
- MVVM-подобный подход к построению архитектуры с разделением ответственностей View и ViewModel хорошо подходит для реализации сложного интерактивного интерфейса.
Целиком проект с демоприложением можно найти на GitHub по ссылке.